Range & Update
通常,使用 HTTP 协议下载一个文件,如果文件很大,差不多 1G,下载器会同时发送多个带 Range 的请求,并行的下载文件的不同片段,等到所有片段下载完成之后,把它们拼接起来就是一个完整的文件了。这是很常见的做法,无非就是多占用局域网、服务器的带宽。断点续传、上传都是这么搞的,做法类似。
想想,如果在下载文件的过程中文件被更新了会怎么样?
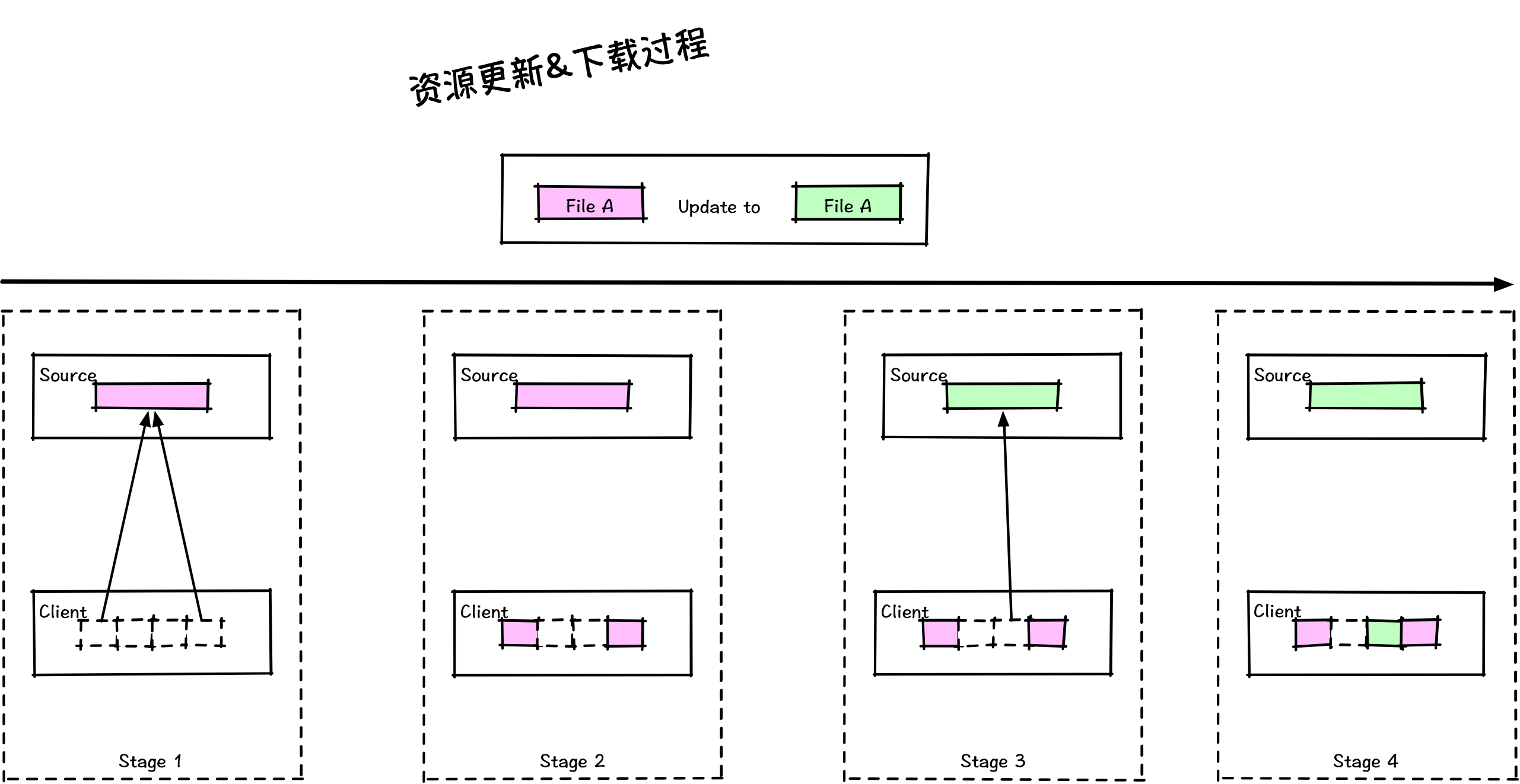
图 1 - 并发下载
先假设下载器不会同时下载所有片段,那么在只下载了前 N 个片段后,资源被更新,接着再下载剩余片段,等到把所有片段都下载完,最终拼接出来的文件就是错误的(也有可能下不完)。这种情况称为”同名文件更新“,在这个过程中并发下载会得到不同版本的内容。同名更新&并发下载,同时满足这两个条件就一定会出现这种问题。一旦发生这种问题,下载器会得错误的数据,也因此需要下载器主动检查 ETAG 来判断得到的内容是不是来自同一个版本,如果不是就需要重新下载。
Cache & Slice
nginx 有个 slice 模块使用了类似的机制。它可以缓存客户端实际需要的内容,而不是全部内容。 什么意思?假设文件大小为 1024 个字节,客户端发起带有 Range: 0-99 的请求,面对这种请求缓存节点要把 1024 个字节都存下来,再响应客户端所需要的内容。有了 slice 之后实际只用保存这 100 个字节,等于是客户端请求什么就存什么,不用把整个资源都缓存起来。提高了缓存空间的利用率,也相对的提高了资源命中率。
缓存对象与资源是一一对应的,可以看作是个实实在在文件,而 slice 是将资源拆成了 N 个固定大小的缓存对象,等于变成了 N 个文件。等到缓存淘汰时,可以不用像以前一样把整个资源淘汰,可能会只淘汰某一部分。
使用 slice 还会出现比一个较麻烦的“不一致”问题。假设目前缓存中只有资源的某一部分内容,恰巧客户端请求的那部分内容正好不存在,缓存节点就会转发到源获取数据。与此同时源又更新了这个资源,缓存节点等于同时拥有两个版本的数据。对于这种问题,slice 实现上会检查 ETAG 来识别问题,再加上缓存实现上会优先响应已有的部分数据给客户端,如果发现问题了就会立刻终止客户端的请求,直到用把所有资源清除才行。就目前而言,一旦出现这个问题,必须通过外部手段(PURGE)清除缓存。
其实 slice 最适合的是那种发布之后不会再有更新的场景,比如:视频、音频。但是严格来说这种场景应该不存在吧?
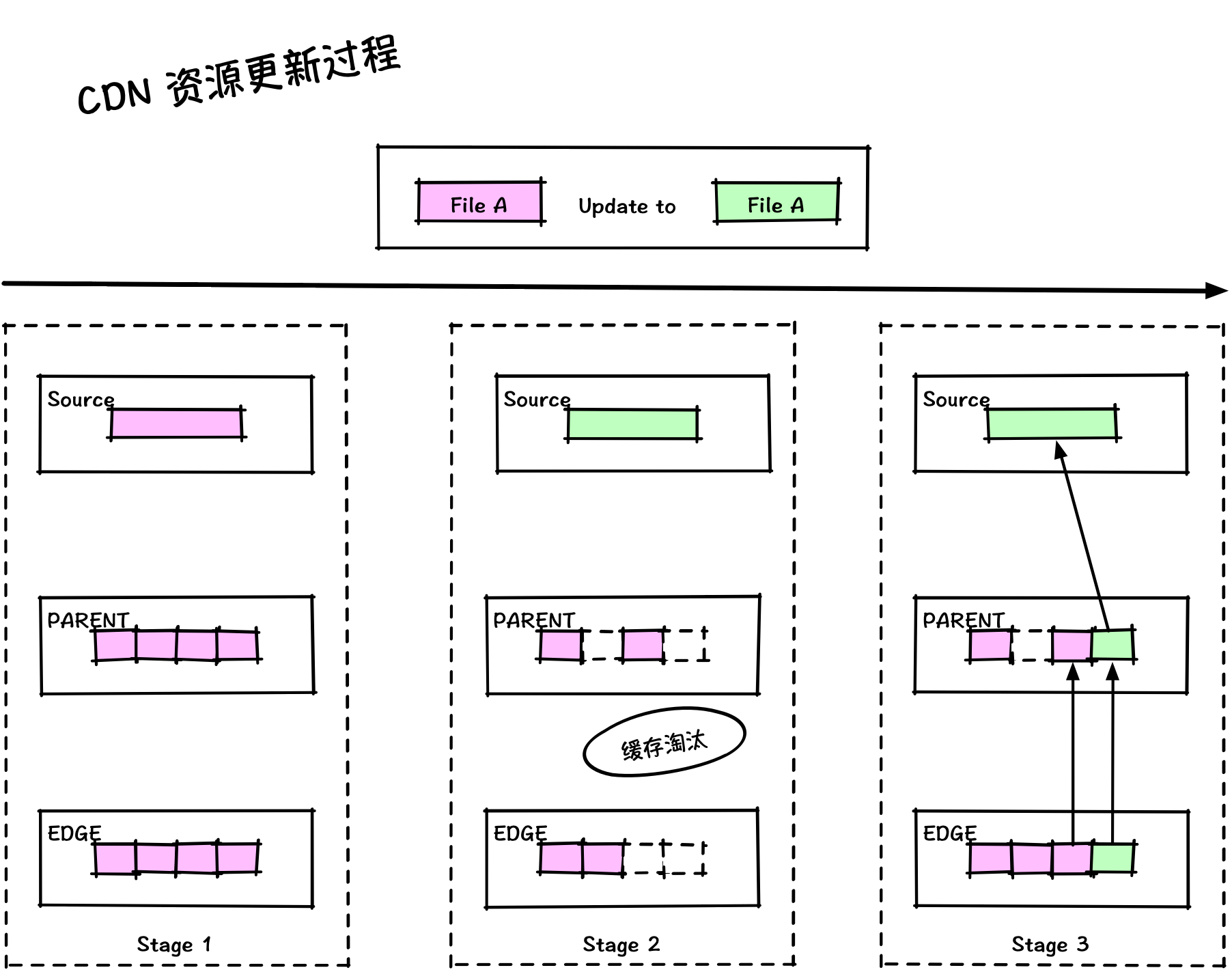
图 2 - CDN 资源更新过程
注:这种情况在启用 slice 之后很常见,在完全清除之前会一直中断客户端的请求。
- Stage 1 :文件 A 与 PARENT、EDGE 缓存中的对象是一致的,只不过被 slice 分成了 N 个独立的缓存对象
- Stage 2:文件 A 内容已经变更,这种时候缓存可能会出现淘汰,但并没有淘汰所有 slice 缓存对象
- 因为是独立对象,PARENT 和 EDGE 淘汰的对象是不一致的
- Stage 3:当淘汰发生的时候,回源取数据,得到了新的内容,这个时候缓存中的文件 A 内容会出现两个版本的内容
- PARENT 和 EDGE 不一致的地方并不相同
所以 CDN 服务一般都会要求客户在更新资源后,必须要提交刷新任务,清除 CDN 上已缓存的资源。不过即使这样做了,从客户端的角度来讲还是有可能得到不正确的内容,因为执行清除任务与客户端请求的时机不可控制,这种手法也只能缩短问题持续时间。
要完全避免这个问题,要么:
1. 不要并发下载一个资源
2. 调度策略使用 hash 算法
3. 每个资源都需要使用新的发布名称,可以带版本号、URL 中加上 md5 之类的
第 1 条:为什么不并发下载就不会有问题?文件系统保证的。这条其实可以忽略,对于较大的文件是不可能每次都从头开始下载。
第 2 条:即便是 CDN 不使用 slice 这种机制,要让所有节点同步,也是非常困难的。如果忽略节点调整,使用 hash 算法来调度请求,也是可以避免的。
第 3 条:每次更新都使用不同的名字,好像比较完美,而且同时还能一并消除链路上的各种缓存的通病:“为什么资源没有更新,CDN 刷新了,还是得到旧资源”。