译者序
在 Linux 系统上用来追踪、调试的工具有很多,有内核态的、用户态的、网络、IO 等等不同层次的工具。本文翻译自 Linux tracing systems & how they fit together - Julia Evans,这是在学习 Systemtap 原理时找到的资料,文章中就粗略讲了 Linux 的追踪系统,以及一点点来龙去脉,实际上工作中用到的大部分工具或多或少都是基于文章当中提到的某一种机制实现的。
注:因为水平有限,文中难免存在遗漏或者错误的地方。如有疑问,建议直接阅读原文。
我对于 Linux 追踪系统一直很困惑,有好几年了。strace、ltrace、kprobes、tracepoints、uprobes、ftrace、perf、eBPF,它们怎么串联在一起的,又有什么意义呢?
上周,我去了"Papers We Love"1,后来我 & Kamal 到蒙特利尔理工大学(LTTng 项目开始的地方)与 Suchakra 一起出去玩,终于我想我理解了所有的这些部件是如何组合在一起的了,或多或少吧。不过,在这篇文章中依然会有一些错误,如果发现了请让我知道!(twitter ID:b0rk)。
这篇文章我要把 strace 抛开(它是我最喜欢的工具),因为开销太高了 - 在这篇文章中我们只会讨论相对高效/低开销的追踪系统。这篇文章也不是关于样本采集器的(这是另外一个主题!)。只是追踪。
我上周学到的东西帮助我真正的了解了 —— 你可以把 linux 追踪系统拆分为数据源(追踪数据的来源),收集数据源的机制(类似 ftrace)和追踪前端(以交互式方式收集/分析数据的工具)。整体看上去还有些零散和模糊,但至少是一个更容易理解的方法。
以下是我们将要讨论的内容:
- 图片版本
- 能追踪什么?
- 数据源:kprobes, tracepoints, uprobes, dtrace probes 等等
- 收集"真香"数据的机制
- 前端
- 所以我应该使用什么样的追踪工具
- 希望这篇文章有用!
这仍然有点复杂,但以这样的方式分解它,确实有助于我理解(感谢 Brendan Gregg 在 Twitter 上建议这样分解!)
图片版本
这里有 6 个草图,汇总了这篇文章的内容:
-
数据源、提取方法、前端

-
数据源:kprobes、uprobes、tracepoints、USTD

-
提取方法:ftrace 文件系统、perf_event 系统调用、eBPF 程序

-
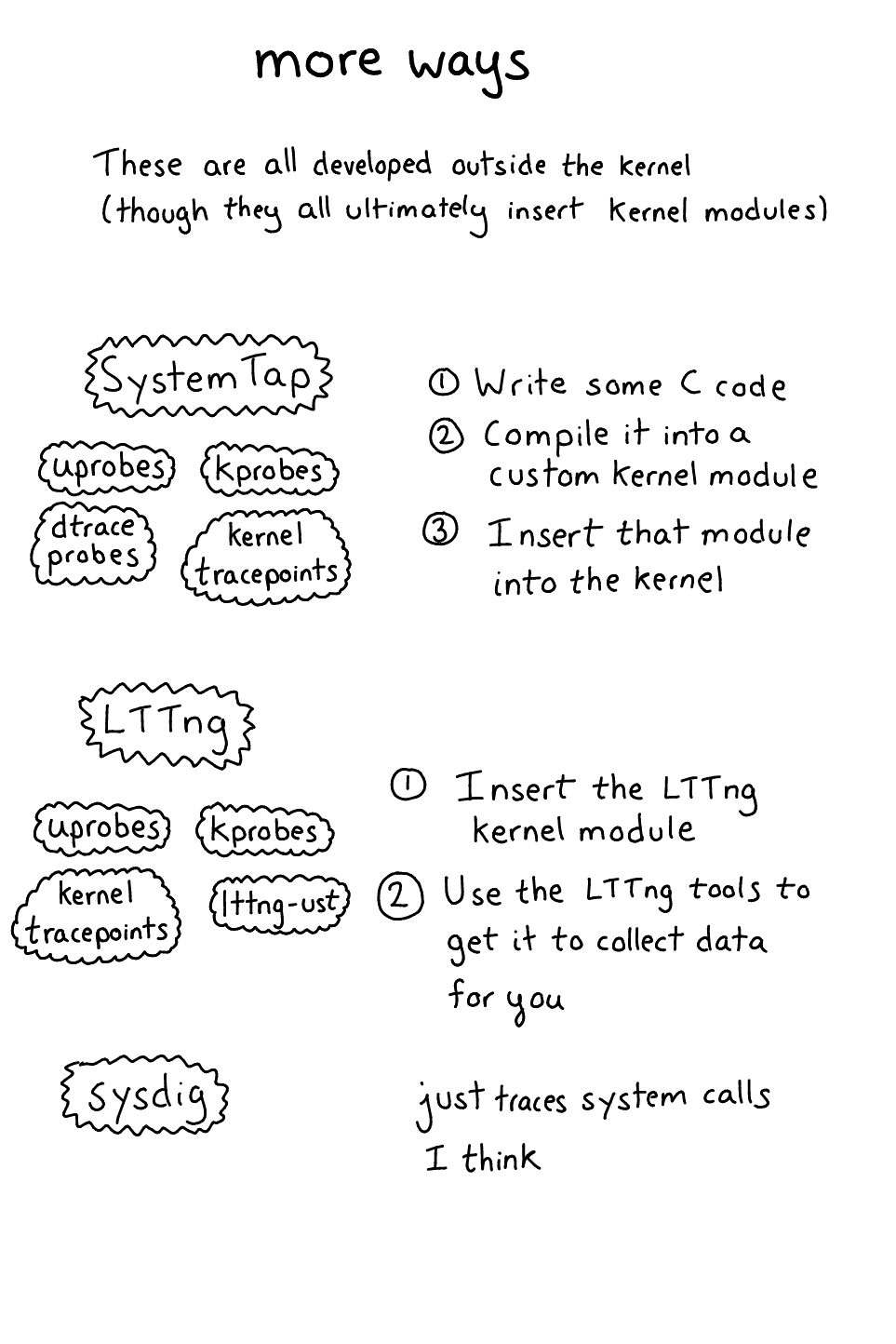
更多方式:Systemtap 脚本、LTTng 工具、sysdig 命令
-
前端:更容易使用、更友好的显示数据
-
更现代的前端

能追踪什么?
你也许想要追踪几种不同类型的事情:
- 系统调用
- Linux 内核函数调用(TCP 栈中的哪个函数正在被调用?)
- 用户空间函数调用(
malloc被调用了吗?) - 在用户空间或是内核空间自定义的"事件"
以上所有事情都是可能的,不过追踪环境实际上是非常复杂的。
数据源:kprobes, tracepoints, uprobes, dtrace probes 等等
Okay,让我们谈谈数据源!这是最有意思的部分——有太多地方可以获取程序的数据。
我要把它们分成 “probes”(kprobes/uprobes)和 “tracepoints”(USDT/kernel tracepoints/ltng-ust)。实际上,我认为我没有使用正确的术语,这有 2 个不同的概念能帮助你去理解。
“probe” 是一种机制,内核可以在运行时修改你的汇编程序(类似,改变指令)来开启追踪。这点非常强大(有点可怕!),因为可以在你追踪的程序任意指令上启用一个 probe。(不过 dtrace probes 不是这种形式的 “probes”)。Kprobes 和 uprobes 就是这种形式的例子。
“tracepoint” 是一种编译到你的程序中的东西。当使用程序的人,想要看看 tracepoint 什么时候命中及提取数据的时候,他们可以先"启用"或"激活" tracepoint 。通常,在 tracepoint 没有被激活的时候不会产生任何额外的开销,甚至在它被激活的时候开销也是相当的低。USDT(“dtrace probes”)、lttng-ust 、kernel tracepoints 它们都是这种模式的例子。
kprobes
接下来是 kprobes!那是什么?下面这段话来自 LWN 的一篇文章:
KProbes 是一种 Linux 内核调试机制,也可以用来监控生产系统内部的事件。还能用它来发现性能瓶颈、记录特定的事件、追踪问题等等。
复述一下,基本上 kprobes 能让你在运行时动态的改变 Linux 内核的汇编代码(比如,插入额外的汇编指令),追踪一个指令什么时候被调用。我以为 kprobes 就是追踪 linux 内核函数调用,实际上它可以追踪内核中的任意指令以及检查寄存器。神奇吧?
Brendan Gregg 有个 krpobe 脚本,可以用来玩一玩 krpboes。
例如!让我们用 kprobes 追踪,我们电脑上正在打开的文件。我执行了下面这条命令
|
|
之后,我的电脑立即输出正在打开的文件。干净整齐!
你会注意到 kprobes 接口本身有点晦涩 - 比如,你必须知道给 do_sys_open 的 filename 参数是在 %si 寄存器中,还要取消对这个指针的引用,并告诉 kprobes 系统它是一个字符串。
我认为 kprobes 在以下 3 种情况中很有用:
- 你正在追踪一个系统调用。所有系统调用都有对应的内核函数,比如:
do_sys_open。 - 你正在调试一些网络栈或者文件 IO 的性能问题,且足够了解被调用的内核函数,对你追踪它们很有帮助(不是不可能!毕竟 linux 内核也是代码)。
- 你是一名内核开发者又或者在试着调试不常发生的内核 bug !(我不是一名内核开发者)
uprobes
Uprobes 有点像 kprobes,只不过它不是检测内核函数的,而是检测用户空间函数的(例如 malloc)。可以阅读 brendan gregg 在 2015 年发布的一篇文章.
我对 uprobes 工作原理的理解是:
- 你决定想要去追踪在 libc 中的
malloc函数 - 你要求 linux 内核为你追踪 libc 中的
malloc函数 - Linux 找到 libc 被加载到内存中的副本(应该只有一份,共享给所有进程),然后改变
malloc的代码方便被追踪 - Linux 用某种办法把数据传递给你(稍后我们会谈怎么"要求 linux"以及"用某种办法获取数据"的原理)
你可以用它做的一件事情是监视其他人在他们的 bash 终端中输入的内容,很炫哝!
|
|
USDT/dtrace probes
USDT 全称为"用户级静态定义的追踪",“USDT 探针” 和 “dtrace 探针"是一个东西(有点出乎我的意料!)。你也许已经听过 BSD/Solaris 上 dtrace,其实你也能在 Linux 上用 dtrace 探针。其实,它是一种暴露自定义事件的方法。举个例子,假如你编译正确的话, Python 3 是有 dtrace 探针的。
python.function.entry(str filename, str funcname, int lineno, frameptr)
如果有一个能够消费 dtrace 探针的工具(例如: eBPF/systemtap),和支持 dtrace 的 Python 版本,你就可以自动的追踪 Python 函数调用。很棒对吧!(然而这是一种"假设”————并不是所有编译的 Python 都支持 dtrace 探针的,在 Ubuntu 16.04 中的 Python 就不支持)
怎么判断支不支持 dtrace 探针,根据 Python 文档,其实你可以用 readelf 工具在二进制文件中查找的 “stap” 字符串。
|
|
如果想阅读更多关于 dtrace 的内容,你可以阅读 2004 年的论文,不过我不知道是不是最好的参考。
kernel tracepoints
Tracepoints 也在 Linux 内核中(这有篇LWN 的文章)。这个方法是 Mathieu Desnoyers(他来自 Montreal!)写的。简单来讲,有一个 TRACE_EVENT 宏,它能让你定义追踪点,像下面这样(它对 UDP 失败队列做些事情?)
|
|
我不太明白它是怎么工作的(我认为它涉及面很广),但基本上追踪点:
- 比 kprobes 好的一点,因为它们在内核版本之间更稳定(kprobes 依赖内核代码)(译注:换句话说就是不同内核版本函数会有很大变化,而 kprobes 又依赖于内核符号)
- 比 kprobes 差的一点,因为必须有人维护它们(译注:一般是内核开发人员或者是模块开发人员在关键的位置放置追踪点,以便可以读取关键数据)。
lttng-ust
我还不太了解 LTTng,但我的理解是,以上 4 种东西(dtrace probes,kprobes,uprobes,tracepoints)在某种程度上都需要内核的支持。lttng-ust 是一个追踪系统,它能让你把追踪探针编译到你的程序中,而且所有追踪都发生在用户空间。意味着它更快开销更小,因为你不必做上下文切换。我还没使用过 LTTng,所以这些就是我要说的内容。
收集"真香"数据的机制
要理解你用来收集&分析追踪数据的前端工具,理解把内核中的追踪数据取出来的基础机制是非常重要的。(这就只有 ftrace、perf_events、eBPF、systemtap、lttng 5 个工具)。
让我们从 ftrac,perf_events,eBPF 开始,实际上它们是 Linux 内核的一部分。
ftrace
上面的 ./kprobe 和 ./uprobe 脚本?它们都使用 ftrace 从内核中获取数据。Ftrace 有点像一种名称接口,直接使用它有点痛苦。在 /sys/kernel/debug/tracing/ 内有个文件系统,能让你从内核中获得各式各样的追踪数据。
与 ftrace 交互的基本方法是:
- 把数据写入在
/sys/kernel/debug/tracing/中的文件 - 从
/sys/kernel/debug/tracing/中的文件读出数据
Ftrace 支持:Kprobes、Tracepoints、Uprobes,我认为就是这样。
基于下面 Ftrace 的输出很难做分析:
|
|
perf_events
从内核中获取数据的第二种方法,是使用 perf_event_open 系统调用。原理是:
- 调用
perf_event_open系统调用 - 内核写把事件到一个在用户空间的环形缓冲区中,应用程序可以从中读取数据
我知道的唯一的一件事情是,你可以以这种方式读取 tracepoints。这也就是执行 sudo perf trace 命令时做的事情(每个系统调用都有一个 tracepoints)
eBPF
eBPF 是一种非常先进的获取数据的方式。它的工作原理。
- 你写一段 “eBPF 程序”(通常是 C 语言,或者用一种生成这种程序的工具)
- 要求内核把探针附着到 kprobe/uprobe/tracepoint/dtrace 探针
- “eBPF 程序"把数据输出到一个 eBPF map/ftrace/perf 缓冲区
- 你拥有了自己的数据!
eBPF 非常好,因为它是 Linux 的一部分(不用安装内核模块),而且你可以定义自己的程序,去做任何你想做的奇怪的事情,因此它非常强大。平时是通过 bcc 前端间接使用它,稍后再讨论 bcc。不过 eBPF 只在较新的内核上可用(选择内核的哪个版本,取决于想把 eBPF 程序附着到什么样的数据源)
不同的内核版本提供不同的 eBPF 特性,以下是一份很好的总结:
sysdig
Sysdig 是一个内核模块 + 追踪系统。它能让你追踪系统调用和一些其他的事情?我发现他们的站点有点难用,不过我认为这个文件包含所有 sysydig 支持的事件列表。Sysdig 会告诉你正在打开文件描述符,但不告诉你 TCP 栈的内部细节。
systemtap
我对 SystemTap 的工作原理有点不清楚,所以我们从架构文档开始
- 你决定要追踪一个 kprobe
- 编写一个 “systemtap 程序”,把它编译到一个内核模块中
- 内核模块在插入后,在激活时会从你的内核模块中调用代码创建 kprobes(调用 register_kprobe)
- 内核模块(使用 relayfs or something)打印输出到用户空间
SystemTap 支持:tracepoints、kprobes、uprobes、USDT
支持许多东西!在这篇 选择一个 linux 追踪工具 的文章中对 systemtap 有更多的描述
LTTng
LTTng (linux tracing: the next generation) 是出自 Montreal (巴黎高等理工学院的实验室)!!,让我超级高兴。前几天,我见过一个被称作追踪罗盘的了不起的 demo 工具,它从 LTTng 读取数据。在执行 tar -zxf somefile.tar.gz 命令时,它可以显示程序与系统调用之间的所有 sched_switch 变化过程,而且真的可以以一种非常清晰的方式看见正在发生的事情。
LTTng 的缺点(类似 SystemTap)是,你必须安装一个内核模块才能使内核的部分正常工作。使用 lttng-ust 时发生的一切都在用户空间,而且没有内核模块(译注:systemtap 会编译出一个内核模块)。
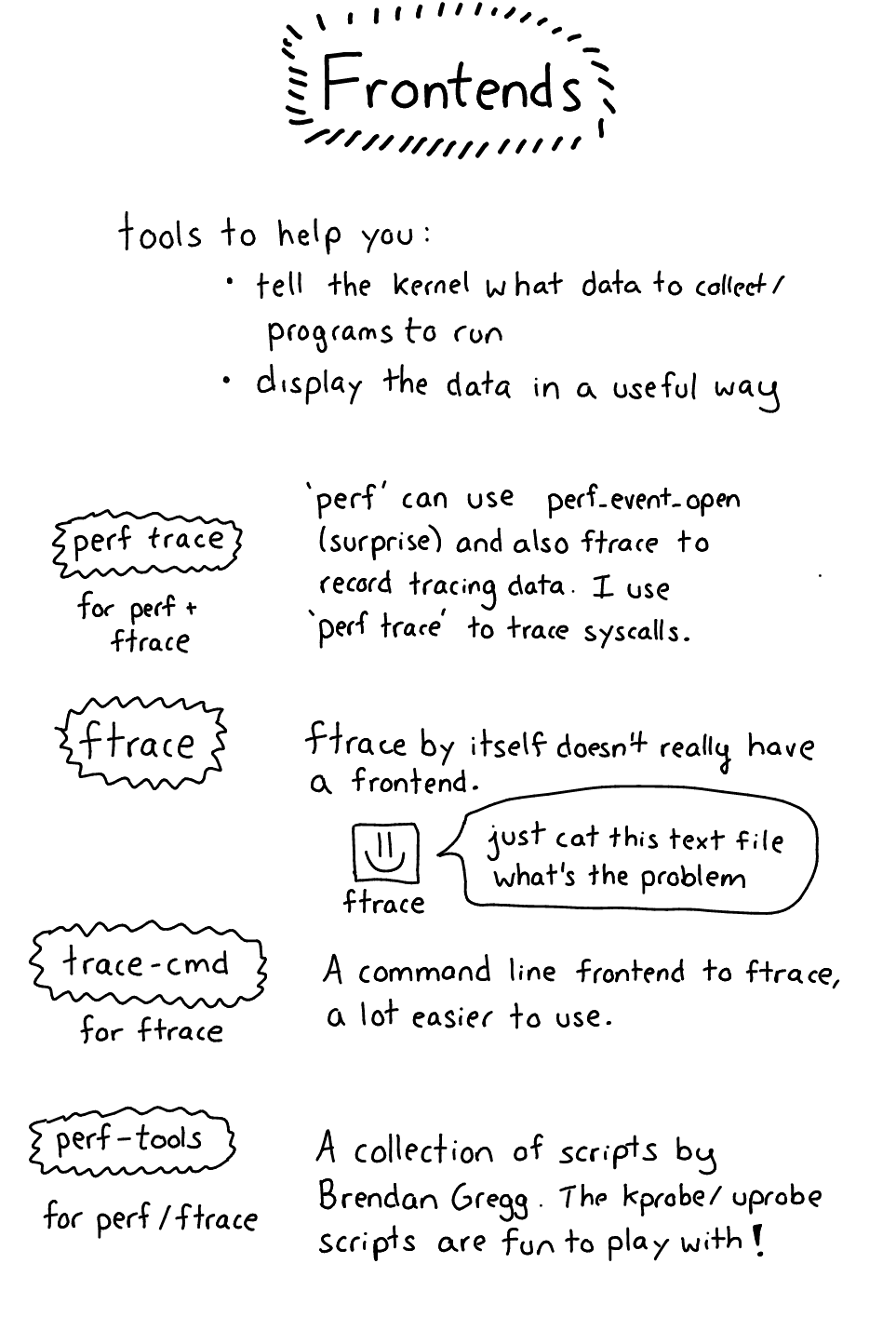
前端
Okay!该谈前端了!我要把他们按照机制(怎么将数据从内核中取出来)分类,理解起来更容易一点
perf 前端
这儿唯一简单的前端是 perf 。
perf trace 迅速为你追踪系统调用。简单,喜欢。实际上,现在 perf trace 是这些前端当中的唯一一个我每天都在使用的工具。(ftrace 这个东西非常强大,但也更难以使用)
ftrace 前端
Ftrace 用起来有点痛苦,因此也有各式各样的前端工具可以帮到你。我还没发现最好的工具,不过可以从下面这些开始:
- trace-cmd 作为 ftrace 的一种前端,你可以用它收集和显示 ftrace 数据。在这篇文章中我写了一点,另外在 LWN 上有一篇关于它的文章
- Catapult 能让你分析 ftrace 的输出。最初它是为了分析 Android/chrome 性能,但你也可以只分析 ftrace 。目前为止,唯一要做的事情就是绘制
sched_switch事件图,以便知道实际是哪些进程在运行,以及它们在哪个 CPU 上。我还没有真的使用过,哪个更好? - kernelshark 消费 ftrace 的输出,只是我还没有尝试过
- perf 命令行工具是一个 perf 前端,并且还是一些 ftrace 功能的前端(有点乱)(见 perf ftrace)
eBPF 前端: bcc
我唯一了解的是 bcc 框架:https://github.com/iovisor/bcc。它能够让你编写 eBPF 程序,帮你把它们插入到内核中,然后它会帮你把数据从内核中读出来,让你可以用 Python 脚本来处理。这框架非常容易上手。
如果你好奇 tcpdump 中的 BPF 和 eBPF 的关系,可以看看前几天我写过一篇它们之间关系的文章。不过我认为最简单的是把它们看作是两个东西就好,因为 eBPF 强大的多。
bcc 有点怪异,因为你要在 Python 程序内部写一个 C 程序,不过倒是有很多例子可以参考。前几天 Kamal 和我第一次用 bcc 编写了一个非常简单的程序。
LTTng & SystemTap 前端
LTTng & SystemTap 都有一套它们自己的工具,我不太了解。说真的————这个被称作追踪罗盘的图形工具,它好像真的很强大。它消费一种 LTTng 产生的数据,称作 CTF(“通用追踪格式”)追踪格式。
所以我应该使用什么样的追踪工具
我现在的想法是(你应该知道,我只是刚刚弄清楚它们如何组装在一起的,我不是专家):
- 如果你计算机中主要运行 > linux 4.9 版本的内核,可能只用学习 eBPF
perf trace它可以追踪系统调用,低开销,且非常简单,么有太多要学的。A+。- 至于其他的,都是一种投资,要花些时间来学习。
- 我认为 kprobes 用来玩玩还是可以的(eBPF/ftrace/systemtap/lttng/ 等方式,对于我来说 ftrace 是最简单的)。能够知道在内核中发生的一切是一种很好的超能力。
- eBPF 只在 4.4 以上的内核版本中可用,且有些特性只在 4.7 以上。我想是有意义的,投资学习它,但在比较旧的系统上,它还不能帮助你
- ftrace 有点太痛苦了,不过对于我来说如果可以找到一个好的前端工具它是有价值的,但是还没找到
希望这篇文章有用!
我真的很高兴,现在我了解了(大部分)所有的组件是如何组装在一起的,这篇文章是我在爵士音乐节上的一场免费的表演中写的,听着布鲁斯过的很愉快。
现在,我知道它们是如何组合在一起的,我认为我可以更轻松的跟进追踪前端的进展!
Brendan Gregg 的博客中有大量的这些主题中的细节——如果你有兴趣了解 linux 追踪生态中的改进(一直在变化!),那是最好的博客。
感谢 Annie Cherkaev, Harold Treen, Iain McCoy, David Turner 阅读这篇文章的草稿。
-
译注:Papers We Love 是一个计算机科学论文网站,经常组织线下活动 ↩︎